Fable 5 で自己改善するエージェントシステムを作る 14 ステップ
— ループ・Dynamic Workflows・Routines
大半の人は Claude Fable 5 を「コンテキストウィンドウが大きい Sonnet 4.6」として使っている。プロンプトして、5 分動かして、タブを閉じる。これは、Fable 5 が本来設計された「複利するシステム」を作るためのロードマップ全文である。
TL;DR
- Fable 5 は数日単位の自律稼働のために作られた、最初の Mythos クラス一般公開モデル。数分で閉じる使い方は Mythos 級の価格を捨てている。
- 自己改善 (self-improving) ≠ 自己学習 (self-learning)。モデルの重みではなく「モデルの周囲のシステム」(メモリ・Skill・eval ループ) が走るたびに複利で鋭くなる。
- 鍵は 3 つのプリミティブ —
/goal・Outcomes のループ、Dynamic Workflows、Routines — に、独立 verifier・STATE.md・vision 自己検証を重ねること。
00導入 — 10 人中 9 人は「複利するエージェントシステム」を知らない
14 steps. 3 tiers. Stop prompting. Start building a system that compounds.
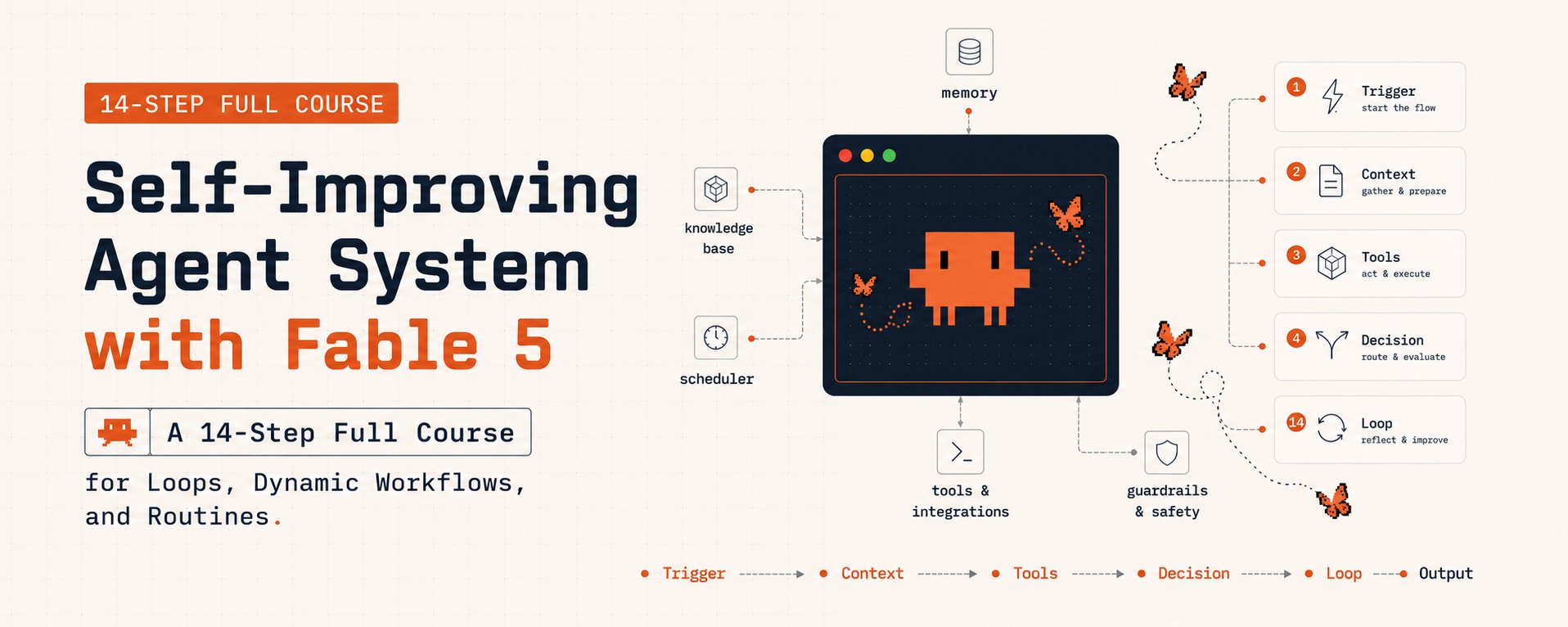
大半の人は Claude Fable 5 を「コンテキストウィンドウが大きい Sonnet 4.6」のように使っている。プロンプトする。5 分動く。タブを閉じる。
10 人中 9 人のユーザーは、複利するエージェントシステム — すべての実行が次の実行を賢くし、すべての state file が蓄積し、すべての Skill が鋭くなるシステム — を一度も運用したことがない。
Fable 5 は数日間走り続けるために作られた。あなたはそれを数分しか使っていない。これは、Fable 5 が設計された自己改善システムを構築するための 14 ステップのロードマップだ。
Claude Fable 5 は 2026 年 6 月 9 日にローンチした — 一般公開された最初の Mythos クラスモデルであり、Anthropic が Opus の一段上に置いた tier である。
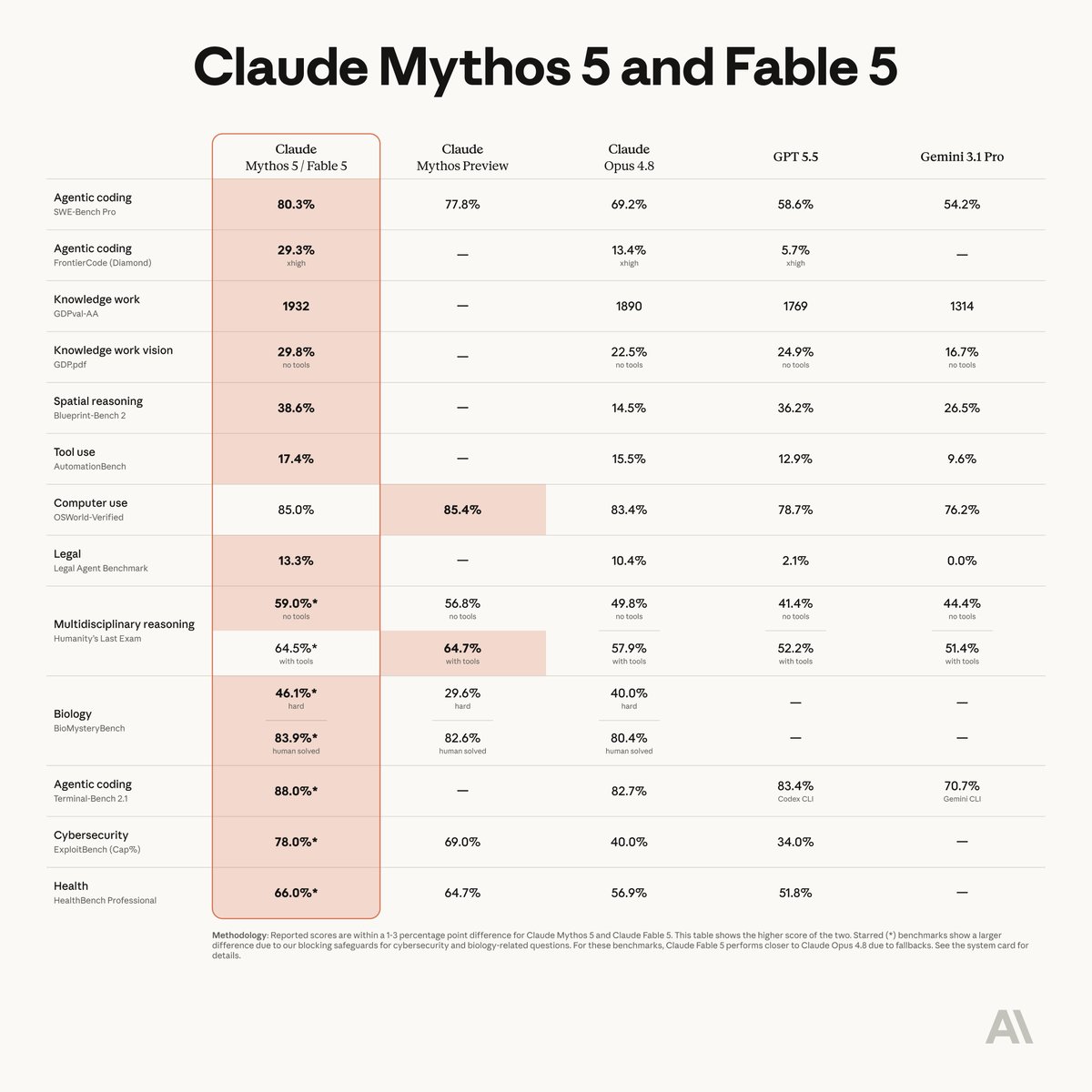
このロードマップは、Anthropic のエンジニアリング記事・チームの公開実験に基づき、2026 年 6 月時点のローンチドキュメントに照らして検証されている (原文著者による)。
3 つの tier で構成される: Fable 5 が実際に解放するもの、それを複利させる 3 つのプリミティブ (ループ、Dynamic Workflows、Routines)、そしてシステムへと変える自己改善レイヤー。

14 steps. 3 tiers. プロンプトするのをやめて、複利するシステムを作り始めよう。
01Fable 5 は Mythos クラスのモデル。「数日単位の自律性」がヘッドライン
2026 年 6 月 9 日ローンチ。Anthropic が Opus の一段上に導入した tier、その最初の一般公開版。

Mythos Preview は 4 月に Project Glasswing を通じて一握りの重要インフラパートナーに出荷された。Fable 5 は Anthropic が一般公開に足ると判断した版で、高リスク領域のリクエストを拒否する安全クラシファイアを内蔵する。クラシファイアを持たない Mythos 5 は Glasswing 限定のままだ。
Anthropic のローンチドキュメントによる、従来の Claude モデルには持続できなかった Fable 5 の能力:
- 数日単位の自律セッション。Claude Code や Claude Managed Agents (CMA) のようなエージェントハーネスの中で、Fable 5 は数日間働ける — ステージをまたいで計画し、サブエージェントに委任し、自分の作業を自分で確認しながら。
- 自己検証の内蔵。自分の作業を確認するテストを自分で書く。vision を使って出力を目標と照合する。教訓を一般則に蒸留する。自分の仮定を検証する。
- 最も野心的なコード作業。大規模マイグレーション、複雑な実装、複数日の自律コーディングセッション。Anthropic が掲げる旗艦ユースケースは「大きなプロジェクトを引き渡し、完成した成果物をレビューする」。
- 多段のナレッジワーク。深いリサーチ・分析から、レビュー可能な成果物まで — 最小限の監督で。
価格は tier に見合う: 入力 $10 / 100万トークン、出力 $50 / 100万トークン。プロンプトキャッシュによる既存の入力 90% 割引はそのまま適用。
提供面は Claude API、AWS、Amazon Bedrock、Vertex AI、Microsoft Foundry、そして従量課金の Enterprise プラン。これはサブスクリプションのモデルではない。ヘビーユースには相応の請求が来る。
※ 価格・提供面・日付はいずれも原文スレッドの記載値 (Anthropic launch docs 由来とされる)。
02self-improving は self-learning ではない
「自己改善エージェントシステム」という言葉は雑に使われる。実在する版と誇大宣伝の版はまったくの別物で、その差は何かを作る前に理解する価値がある。
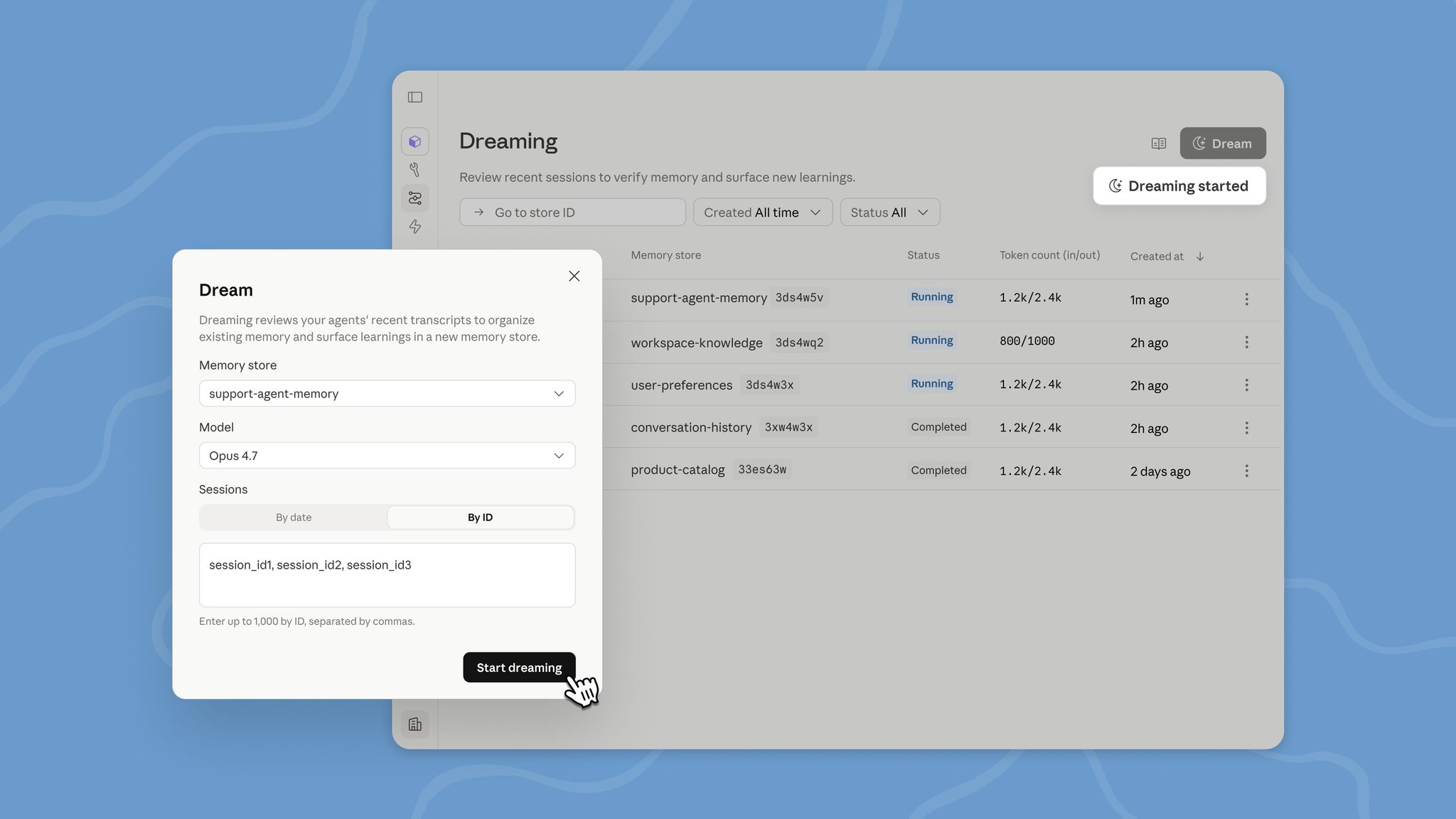
- Self-learning — エージェントが学んだことに基づき自分の重みを更新する。Fable 5 はこれをやらない。本番でこれをやる公開モデルは存在しない。再帰的自己改善 (RSI) は Anthropic 自身が 2026 年 5 月に警告した長期的な方向性であって、今日出荷されている能力ではない。
- Self-improving — エージェントの周囲のシステムが複利する。各セッションが教訓をメモリに書く。エッジケースが追加されるたびに Skill が鋭くなる。state file に検証済みの事実が蓄積する。eval ループがプロンプトとルーブリックを改良する。モデルは同じまま、モデルが走る環境が鋭くなる。
この意味での自己改善は、あなたが作るシステムの性質だ。Fable 5 が持つのは生の能力 — 長いコンテキスト、サブエージェント委任、vision 自己チェック、数日のスタミナ — であり、それが環境フィードバックのループを「実際に走るたびに複利するもの」へ変える。
“Rather than directly prompting and steering Fable 5, it’s often better to design loops that let the model self-correct in response to environment feedback (e.g., /goal or Outcomes) and manage its own context (e.g., via memory).”
(Fable 5 を直接プロンプトして操縦するより、環境フィードバックに応じてモデルが自己修正できるループ (例: /goal や Outcomes) と、自分のコンテキストを自分で管理する仕組み (例: メモリ) を設計するほうが良い場合が多い)
03compound stack: 4 つの層、1 つのフィードバックループ
冒頭の Figure 1 がこのアーキテクチャを 1 枚で示している。下から上へ読む — それがシステムを構築する順序であり、レバレッジが複利する順序だ。
| 層 | 中身 | 役割 |
|---|---|---|
| Layer 1 · Primitives | Fable 5 本体、サブエージェント、worktree、エージェントが使うツール | システムをまだ持たない生の能力。大半の人が今日使っているのはここだけ |
| Layer 2 · Orchestration | 自己修正ループのための /goal と Outcomes。複雑な多段オーケストレーションのための Dynamic Workflows。ラップトップを閉じたままのクラウド実行のための Routines | プリミティブをワークフローに変える |
| Layer 3 · Memory | state file、Skills、Knowledge Bases、書き留められた教訓 | 明日のセッションが「やり直し」ではなく「再開」になる理由 |
| Layer 4 · Self-improvement | vision 自己チェック、eval ループ、ルールの蒸留 | エージェントが自分の出力を採点し、それを生んだ Skill を改良し、教訓をメモリに書き戻す。ループが閉じる |
このアーキテクチャが複利する理由: Layer 1 のすべての出力は Layer 4 へ流れ、そこで採点・蒸留され、Layer 3 に書き戻される。明日の Layer 1 の実行は、昨日研がれたメモリと改良された Skill を継承する。モデルはステートレスだが、その周囲のシステムはそうではない。
04Fable 5 vs Opus 4.8 vs Sonnet 4.6 をいつ使うか。コスト能力マトリクス
Fable 5 はトークンあたり Opus 4.8 の約 5 倍のコスト。自己改善システムのすべてのステップに最上位 tier が要るわけではない。本番運用しているチームは「デフォルトで」ではなく「タスクの複雑性で」ルーティングする。
| モデル | 担当 | 具体例 |
|---|---|---|
| Fable 5 | 重量級 orchestrator 役 | 数日にわたる計画、サブエージェントへの委任、vision での作業確認、蓄積された証拠からのルール蒸留。「days at a time」の能力が価格に見合う場所でだけ使う |
| Opus 4.8 | 難しいが境界のあるサブタスク | アーキテクチャ判断、複雑なデバッグ、深いコードレビュー。さらに Fable 5 のクラシファイアがブロックするリクエスト (cyber・bio・chem・蒸留) の明示的なフォールバック先 |
| Sonnet 4.6 | 大量のワーカータスク | lint 修正、単純なリファクタ、テストの雛形づくり、ドキュメント更新。fan-out 作業の大半はここで走る |
| Haiku 4.5 | grader サブエージェント・安価なクラシファイア | 独立したコンテキストウィンドウと低コスト — Anthropic が明示的に推奨する verifier 役に理想的 |
自己改善システムを経済的に成立させるコストパターン (本番運用チームが使用): orchestrator は Fable 5、worker は Sonnet 4.6、grader は Haiku 4.5、クラシファイアのブロック時は Opus 4.8 にフォールバック。Anthropic のエンジニアが社内で使うのと同じパターン。
05/goal vs Outcomes。同じ思想の 2 つの実装
Anthropic の Claude Code チームは、ゴール駆動ループのためのほぼ同一なプリミティブを、ハーネスごとに 1 つずつ公開している。

両者は同じ形を共有する: 独立した grader が作業をチェックし、「未達」の判定が次のイテレーションを開始し、grader が合格を出したらループを抜ける。実装の差は「どちらを使うか」を決める表面的な詳細にある。
/goal (Claude Code) | Outcomes (CMA) | |
|---|---|---|
| どこで走るか | 手元のマシン。クイックなインセッションループ | Anthropic ホストのインフラ。サンドボックス・GPU・統制された環境で数時間〜数日 |
| 向いている作業 | hands-on のコーディング、flaky テストのデバッグ、単一ファイルの洗練 | ML 訓練、長時間のマイグレーション、複数日のリサーチ |
| ゴールの形式 | プレーンテキストのゴール | ファイルベースのルーブリック (採点可能な基準) |
| grader | モデル grader、ターミナル内フィードバック | サブエージェント grader、ハードな max_iterations 上限 |
両者が機能する構造的なムーブは共通: コードを書いたエージェントが、それを採点するエージェントではない。それがなぜ重要かは step 06 で掘り下げる。
06verifier サブエージェントは self-critique に勝つ
Anthropic エンジニア Prithvi Rajasekaran はエンジニアリングブログで「モデルは自分の出力の自己批判が苦手」だと示した。Claude Code チームはこれを Fable 5 で実証的に確認した。
(Fable 5 では verifier サブエージェントが self-critique を上回る傾向がある)
メカニズムは「もっと頑張る」の話ではなく構造的だ。自分の出力を評価するモデルは自分の推論の軌跡が見えており、すでに書いたことと整合する結論を好む。同じ出力を評価する別のモデルには、成果物とルーブリックしか見えない。verifier は maker のゲームに利害 (skin in the game) を持たない。
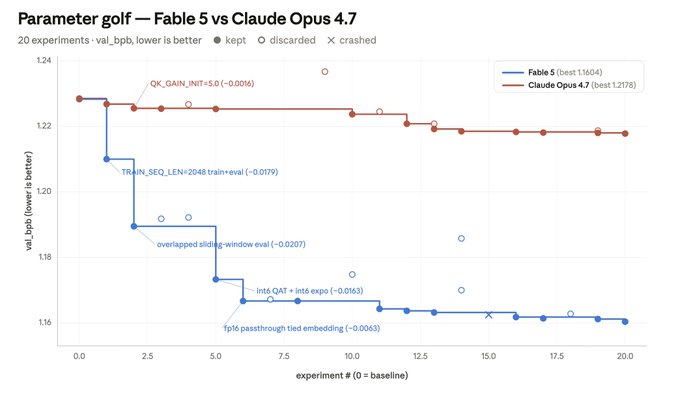
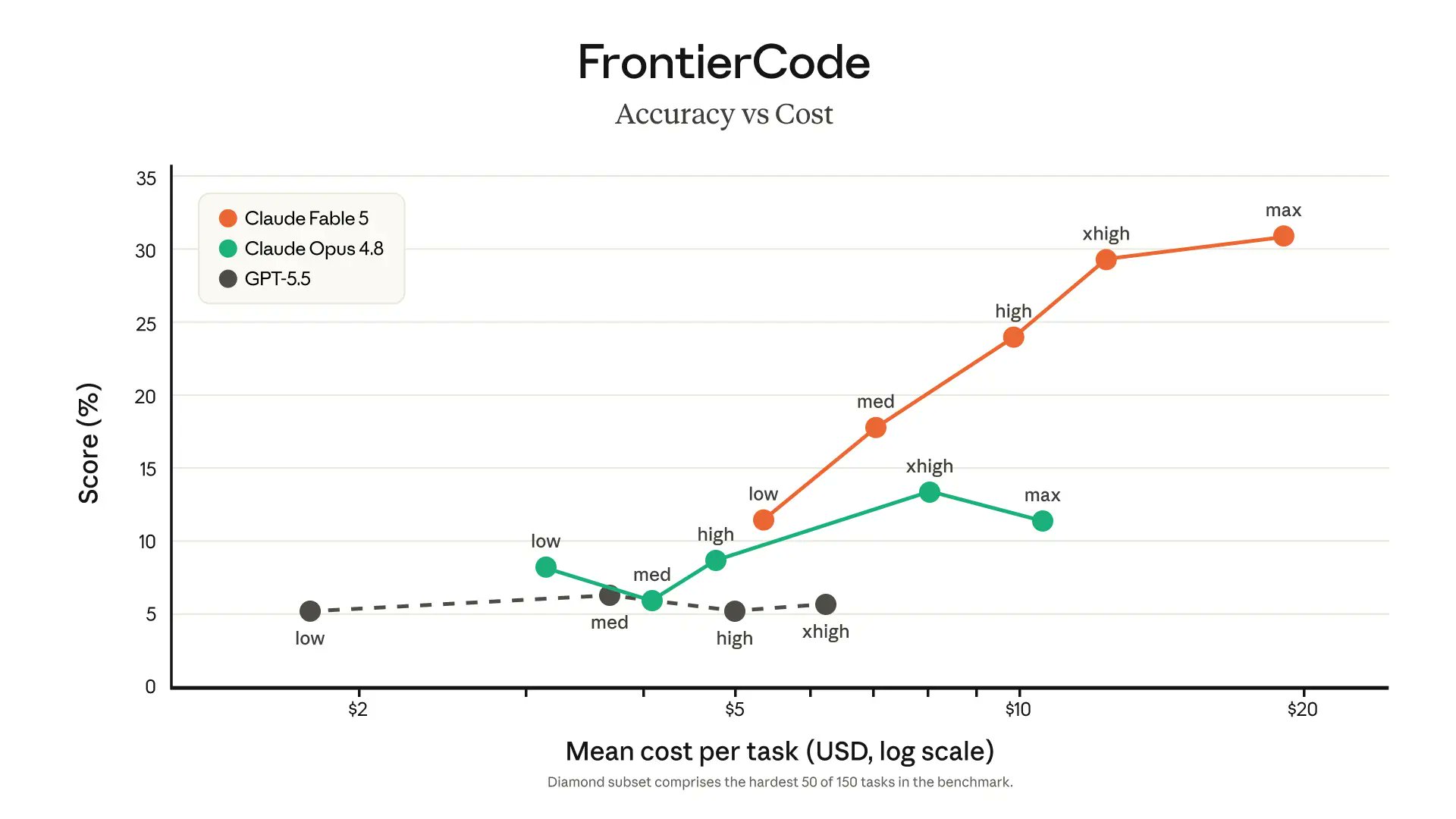
チャートがヘッドラインの数字以上に示していること:
- Fable 5 はより大きな構造的変更を行った — TRAIN_SEQ_LEN=2048 train+eval (−0.0179)、overlapped sliding-window eval (−0.0207)、int6 QAT + int6 expo (−0.0163)。いずれも定数いじりではなくアーキテクチャレベルの一手。
- Fable 5 は量子化のリグレッションを突き抜けて最大の勝利に到達した — 失敗した実験の後に revert するのではなく、調査を続けた。
- Opus 4.7 の最初の実験 (QK_GAIN_INIT=5.0) は小さな勝ちを出した。その後はほぼすべて同じテンプレート: スカラーを調整し、測定し、正なら維持。この形は「より安全」なだけで「より良い」わけではない。
システム設計上の教訓: 独立 verifier を付けた Fable 5 は、より大きな仮説空間を探索し、負の中間結果から回復する。verifier がなければ、同じモデルに最初の「good enough」を超えさせる強制力は何もない。
07Dynamic Workflows は自己修正パターンを合成する
Dynamic Workflows は 2026 年 5 月 28 日に Claude Code へ出荷された。
アイデアはこうだ: Claude が自分の JavaScript ハーネスをその場で書く — agent()、parallel()、pipeline() のプリミティブに、間を流れるデータを処理する標準 JS を加えたファイル。ハーネスは汎用品ではなく、そのタスク専用に作られる。
私たちの最も強力な新しいClaude Code機能「dynamic workflows」をお知らせできることを大変嬉しく思います! (原文に引用されたアナウンス)
Fable 5 での自己改善システムにおいて、文書化された 6 つの Dynamic Workflow パターンのうち 3 つが採用に値する:
- Fan-out-and-synthesize。作業を N 個の独立した断片に分割し、それぞれにエージェントを並列で走らせ、結果を統合する。各ステップが自分のクリーンなコンテキストウィンドウの恩恵を受けるときに最良 — 例: Skill 内の各ルールを過去の事例に対して評価する。
- Adversarial verification。maker エージェントごとに、maker の推論を一切見ていない独立 verifier を spawn する。step 06 の自己選好バイアスへの構造的な修正を、タスク単位で適用するもの。
- Loop until done。停止条件 — 新しい発見がない、ログにエラーがない、理論が検証された — を満たすまでエージェントを spawn し続ける。
/goalと組み合わせてハードな完了要件を設定する。
自己改善システムには通常登場しないが知っておく価値のある残り 2 パターン: classify-and-act (クラシファイアでタスクを適切なモデルへルーティング — step 04 のモデルルーティングに有用) と tournament (好みベースのランキングのためのペア比較 — コーディングループでは稀だが、デザインや命名のタスクに有用)。
08並列安全のための worktree。数日の Fable 5 セッションでもファイル衝突なし
自己改善システムが 2 つ以上のエージェントを spawn した瞬間、ファイルの衝突が始まる。2 つのエージェントが同じファイルに書くのは、2 人のエンジニアが相談なしに同じ行へコミットするのと同じ問題だ。
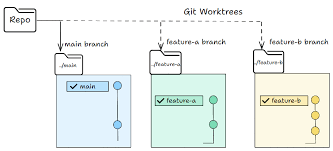
git worktree がこれを解決する — 同じリポジトリ履歴を共有しつつ、自分のブランチを持つ別の作業ディレクトリ。一方のエージェントの編集は、もう一方のチェックアウトに物理的に触れられない。
Fable 5 が検証や専門化のためにサブエージェントを spawn する自己改善システムでは、worktree はオプションではない:
- maker は worktree A に書く。verifier は worktree B で読む (または worktree A のチェックアウトに対して read-only ファイルシステムで走る)。verifier の探索が maker の状態に触れるリスクがゼロになる。
- 並列の構造的実験。Fable 5 が複数のアーキテクチャ変更を探索する場合 (Parameter Golf のように)、各実験は自分の worktree で走る。orchestrator が全結果を収集し、最良のものがマージされる。
- チェックポイント付きの数日ラン。主要フェーズごとに別の worktree にできる。失敗したフェーズが残りを汚染しない。
Claude Code では worktree は 3 通りに公開されている: git worktree を直接使う、--worktree フラグでセッションを専用チェックアウトで開く、そしてサブエージェントへの isolation: worktree 設定 — 各ヘルパーがセッション終了後に自動クリーンアップされる新しいチェックアウトを得る。
09数日オーケストレーションのための Routines。ラップトップを閉じても Fable 5 は働く
Routines は 2026 年 4 月 14 日に research preview でローンチした。保存された Claude Code 設定 — プロンプト、リポジトリ、コネクタ、権限 — が、トリガーに応じて Anthropic 管理のクラウドインフラ上で走る。
あなたのラップトップは電源オフでいい。実行はそれでも起きる。
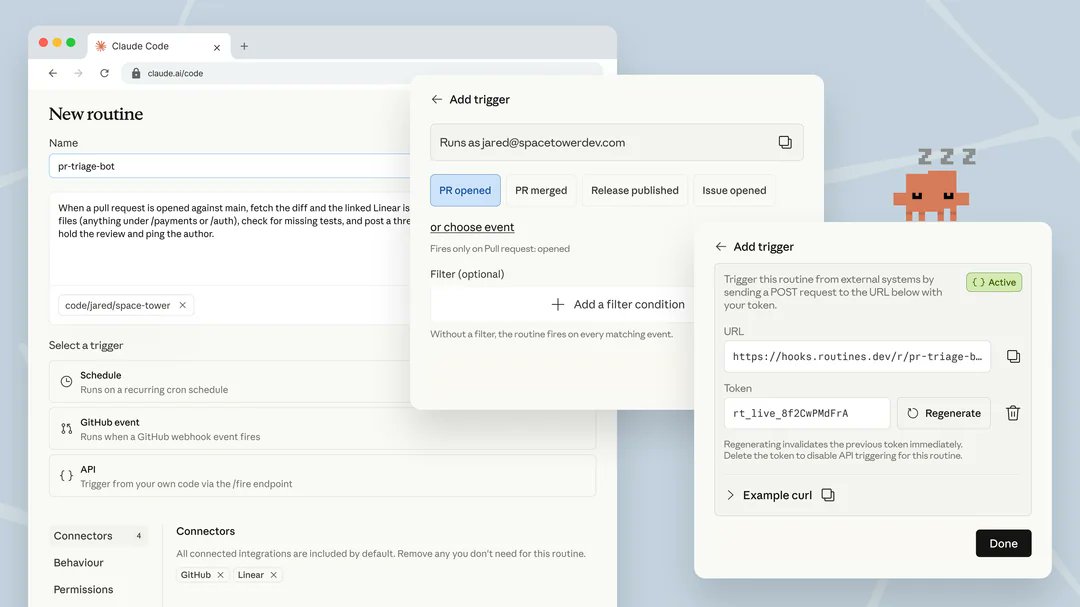
Fable 5 にとって、Routines はモデルの能力を回収するトリガー層だ。Anthropic は Fable 5 の「days at a time」を Claude Managed Agents — フルツールを備え、ローカルマシンの制約がないホスト型サンドボックス — の上で測定している。Parameter Golf 実験は 8×H100 GPU 上で最長 8 時間走った。そのクラスの実行はラップトップでは起きない。
3 つの Routine トリガー型を、自己改善パターンに対応づける:
- Schedule トリガー — 朝のブリーフィングパターン。毎朝 7 時: 昨日の eval スイートを再実行し、新しい failure mode を Skill に蒸留し、ダイジェストを Slack に書く。あなたが寝ている間にエージェントが鋭くなる。
- API トリガー — 「イベントで発火」パターン。CI が失敗 → 調査の Routine を発火。Sentry アラート → トリアージの Routine を発火。自己改善システムが、固定スケジュールではなく実際の環境に反応する。
- GitHub event トリガー — 「実作業から学ぶ」パターン。PR が開いたら最新の Skill に対して評価を走らせる。マージされたら、その PR が持ち込んだ新パターンを Skill に書き戻す。リポジトリの状態と Skill の状態が同期し続ける。
> /schedule daily at 7am, use Fable 5 in CMA Goal: Re-run yesterday’s eval suite against the latest skills. Any test that newly passes → distill the pattern into the skill. Any test that newly fails → investigate, document in STATE.md. Post the digest to #engineering. /goal don’t stop until digest is posted and STATE.md is updated. ▲ Claude Creating routine: nightly-eval-compounding - model: claude-fable-5 - harness: claude managed agent (sandbox) - trigger: schedule (0 7 * * *) - grader: independent Haiku sub-agent (Outcomes) ✓ Active. First run tomorrow 07:00 local. Skill set will compound.
10メモリの 5 段階進行
「エージェントのメモリ」が実務で何を意味するかについて最も有用なフレーミングは、Anthropic チームの Continual Learning Bench 1.0 実験から来ている。メモリの有効活用には 5 段階の進行が必要で、各段階は構造的なムーブであり、モデルごとに進行から離脱する地点が違う。
- 1. Fail — エージェントが何かを間違え、後で役に立つ十分な詳細とともに失敗を文書化する。
- 2. Investigate — 先に進む前に、なぜその失敗が起きたかを突き止める。
- 3. Verify — 診断を、推測ではなく検証済みの事実に変える。
- 4. Distill — 検証結果を、その特定のケースを超えて適用できる一般則に変える。
- 5. Consult — 次のタスクで、事実をゼロから再導出するのではなくルールを読む。
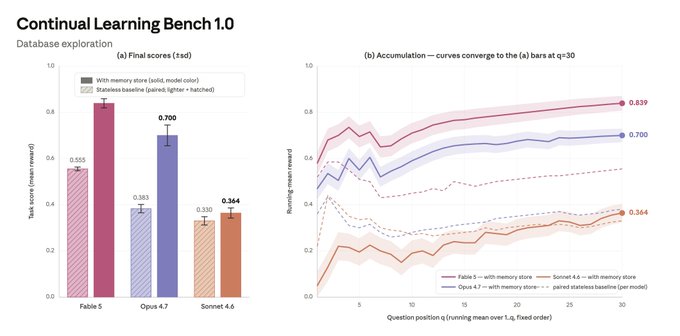
Continual Learning Bench の SQL 探索タスクにおける、メモリを与えられた各モデルの測定差:
| モデル | 離脱点 | 実際の挙動 |
|---|---|---|
| Sonnet 4.6 | step 1 で離脱 | メモリストアは失敗メモと未解決の推測のリスト (「maybe prc instead of prc_usd?」)。過去のノートをほとんど参照しない。メモリは存在するが複利しない |
| Opus 4.7 | step 3 で離脱 | 不確実性をフラグしたスキーマリファレンスを作る (「possibly prc in cents? Verify.」)。検証カバレッジは質問の 7–33% (中央値 ~17%) |
| Fable 5 | 進行を完走する傾向 | 最良のランでは検証カバレッジが 73% (30 問中 22) に達し、将来のタスクに効く一般則へ学びを蒸留する |
11state file。メモリが実際に住む場所
5 段階進行はメンタルモデルで、state file は各段階の出力をモデルが書き込む先だ。CMA で走る Fable 5 にとってメモリはセッション間で生き残るマウント済みファイルシステムであり、ローカルの Claude Code では markdown ファイルや Linear のボードが同じ役割を果たす。
5 段階進行を実際に支える state file の構造 (原文の例・全文):
# Project memory · trading-platform ## Verified facts # stage 3 — stop guessing about these - prc is in dollars, not cents. Verified via SELECT MIN(prc), MAX(prc) FROM trades. - user_id matches auth_users.uid via JOIN, not auth_users.id. Confirmed 2026-06-09. - Test database uses Stripe sandbox keys; production uses real keys via env. ## General rules # stage 4 — consult before re-deriving - When querying time-bucketed metrics, always include timezone (default UTC mismatches). - Auth middleware order matters: rate_limit -> jwt -> rbac. Reversing causes 401s. - For migrations, never use ALTER on tables >1M rows without batching. ## Open failures (investigate next session) # stage 1 → 2 - 2026-06-09: tests/e2e/checkout flakes ~1 in 50 runs. Hypothesis: webhook race. Reproduction steps in debug/checkout-flake.md. ## Lessons learned # stage 4 distillations - PowerShell hits TLS 1.2 issue on Windows CI runners. Always shell out to bash. - Stripe webhook tests require STRIPE_WEBHOOK_SECRET. Skip with clear message if missing. ## Last session # stage 5 — resume, don’t restart 2026-06-10 03:30 UTC · 7 failures classified, 3 fixes drafted (claude/fix-*), 4 escalated. Next: verify the auth middleware fix in claude/fix-rate-limit-order against production load.
このファイルは 5 つの段階に対応する 5 セクションを持つ。Verified facts は stage 3 の出力 — エージェントが推測をやめたこと。General rules は stage 4 — 特定ケースを超えて適用できる蒸留済みルール。Open failures は stage 1–2 の仕掛かり。Lessons learned はさらなる stage 4 の出力。Last session は stage 5 のための再開ポインタだ。
このファイルが実際に複利するか、ただ肥大するだけかを分ける運用ルールは 2 つ:
- 立ち去る前に書く (Write before walking away)。すべての Fable 5 セッションは STATE.md の更新で終わる — 何を試したか、何が通ったか、何が失敗したか、どの新ルールが生き残ったか。書かずに終えたセッションの次は、ゼロからのやり直しになる。
- セッション開始時に読む (Read at session start)。すべての新セッションは STATE.md と最も関連する Skill を読むことから始まる。Continual Learning Bench のデータは、これがないと Fable 5 でさえ Sonnet 級のメモリ挙動に落ちることを示している。
12複利する Skill。教訓はチャットではなく Skill 自体に書く
STATE.md はプロジェクトのメモリ。Skill は手続きのメモリ — プロジェクトを横断して効くべき「この種のことのやり方」だ。
複利のパターン: 非自明な失敗のあとは毎回、教訓を Skill 自体に書き込む。システムが走るたびに Skill が鋭くなる。

2 週間複利してきた Skill は、作りたてのものとは見た目が違う。新しいセクションが現れる: 既知の failure modes、ポストモーテムから生まれたルール、本番で観測されたアンチパターン。Skill はもはや静的な指示セットではなく、チームが実際に学んだことの蓄積記録になる。
--- name: ci-triage description: Classify CI failures, draft fixes for easy ones, escalate the rest. Trigger on workflow_run.failure or on the morning triage routine. --- # CI triage skill ## Classification rules - env: missing secret, wrong env var. # escalate to human, never auto-fix - flake: passes on retry without code change. # retry once, then file - bug: deterministic failure tied to recent commit. # draft fix - dependency: tied to version bump. # draft rollback - infra: timeout, OOM, runner issue. # escalate ## Known failure modes # added by the loop over 14 days - webhook-race: e2e checkout flakes when Stripe webhook arrives mid-test. Fix: add 2s settle delay in tests/utils/webhook.ts. - tls-handshake: Windows runners fail TLS 1.2 in PowerShell. Use bash. - db-migration: ALTER on trades table >1M rows times out at 30s. Batch in 10k chunks. ## Anti-patterns (do NOT do) # added after real incidents - Never disable a failing test to make CI green. File it instead. - Never modify .github/workflows/ without human approval. - Never touch src/payments/ or src/billing/ without security review. ## State Update STATE.md after each run with classifications, fixes drafted, escalations. ## Eval suite # step 13 — the loop verifies the skill Run against eval/ci-triage-cases.jsonl weekly. Any newly-failing case → add to known failure modes after Outcomes verifier confirms.
複利の契約: 確認されたすべての教訓は、STATE.md だけでなく Skill に入る。STATE.md はプロジェクトスコープで、プロジェクトとともに死ぬ。Skill は ~/.claude/skills/ に住み、あなたとともに移動する。規律を持って 2 週間書き続けた Skill は、Fable 5 が新規プロジェクトでゼロから導き出すものを実質的に上回る。
13vision による自己検証。Fable 5 が自分の UI を goal と照合する
Anthropic が Fable 5 とともに出した見出し能力のひとつが「vision を使って出力を目標と照合する」。抽象的に聞こえるが、これが置き換えるものを見れば具体的だ: スクリーンショットを目視して UI が正しいか確かめる人間、である。
Fable 5 はそのステップを、ループの中で、done を宣言する前に、自分でやる。
本番でのパターン:
- maker サブエージェントが UI コードを書く。結果をスクリーンショットにレンダリングする。
- verifier サブエージェントが vision でスクリーンショットを読む。goal の記述、プロジェクト Skill 内の design tokens、STATE.md にある前回のスクリーンショットと比較する。
- 判定 (verdict) がループに戻る。一致 → タスク完了をマーク。不一致 → ギャップを記述し、構造化された diff とともに maker に差し戻す。
このパターンは Anthropic が Parameter Golf 実験で同じハーネスの下で測定したものだ: Fable 5 は訓練チャート (視覚的な成果物) を見て、曲線が基準を満たすかを判断した。ループの中でチャートを読む人間はいなかった。verifier がチャートを読んだ。
14Mythos 安全境界。Fable 5 がやらないこと、そしてその回避設計
最後のステップは、初日に最もスキップされやすく、あとで身をもって学ぶと最も高くつくものだ。
Fable 5 は、特定の高リスクドメイン — サイバーセキュリティ脆弱性研究、生物学、化学、モデル蒸留 — で応答を拒否する安全クラシファイアを内蔵して出荷される。これらのドメインでは、Anthropic は自動的に Claude Opus 4.8 へフォールバックする。これは文書化された仕様であり、バグではない。
自律的に走る自己改善システムにとって、これが意味すること:
- システムがセキュリティツーリングに触れるなら (SAST スキャン、エクスプロイト研究、ペネトレーションテストのロジック、一部のコードレビューさえ)、クラシファイアのブロックを想定せよ。フォールバックを設計する: それらのタスクを明示的に Opus 4.8 にルーティングするか、ブロックを人間のレビュアーに表面化させる。
- 生物学・化学・蒸留ドメインも同様。クラシファイアは広い。科学計算のワークフローが発火させるかもしれないし、暗号プリミティブのコードレビューが発火させるかもしれない。
- Skill がフォールバックを優雅に表面化するように設計せよ。Skill は、自分が生み出すタスクのうちどの種類がクラシファイアに当たりうるかを知っていて、期待される挙動を文書化しているべきだ。クラシファイアのブロックで静かに失敗するループは、本物のエラーで失敗するループと見分けがつかない — デバッグするまでは。
- システムカードを監査せよ。Fable 5 の 319 ページのシステムカードはクラシファイアの範囲を文書化している。2026 年 6 月中旬、一部のダウングレード挙動が文書の中に埋もれた形で発見され、ローンチは論争を生んだ。production に展開する前に読むこと。
一般的な設計原則: 安全境界を failure mode ではなく既知のフォールバックとして扱う。境界の明示的なハンドリングを備えて出荷された自己改善システムは、クラシファイアが進化しても頑健であり続ける。無視したシステムは、Anthropic がポリシーを更新したときに静かなリグレッションを生む。
§よくあるミス 10 項目 (全文)
どれか 1 つでも当てはまるなら、そこが複利の漏れ口になっている。
- Fable 5 を「コンテキストが多い Sonnet 4.6」として使う。5 分のプロンプト&クローズのセッションは、複利効果ゼロのまま Mythos 級の価格を燃やす。
- 独立 verifier の代わりに self-critique。maker が自分の宿題を採点している。Anthropic はその差を測定し、チームは verifier サブエージェントのパターンを明示的に文書化している。
- STATE.md がない。すべてのセッションがゼロから再出発する。Continual Learning Bench のデータは、Fable 5 のメモリ優位の 70% 以上がここで消えることを示している。
- 一度も書き込まれない Skill。静的な Skill 自体は問題ない。だが実際の失敗のあとに教訓が蓄積されない Skill は、無駄な足場だ。
- Sonnet 4.6 で済むタスクに Fable 5。ドキュメント更新、単純なリファクタ、lint 修正。複雑性でルーティングし、Fable 5 は orchestrator 役のために取っておく。
- 長いセッションをラップトップで走らせる。数日単位の能力にはクラウドインフラ (CMA か Routines) が要る。閉じたラップトップはセッションを殺す。
- Mythos 安全境界の無視。cyber/bio/chem でのクラシファイアブロックは静かなリグレッションを生む。フォールバックを明示的に設計せよ。
- 視覚的なタスクに vision-verify がない。UI、ダッシュボード、デザイン忠実度 — これらをテキストのみの verifier でチェックすると、本当に重要な failure mode を見逃す。
- /goal や Outcomes を飛ばす。独立 grader がチェックする客観的な停止条件がなければ、ループは「done」ではなく「handled enough (十分対応した)」で止まる。
- 保持ポリシーのレビューなし。30 日 / 2 年の条件を確認せずに機微データを Fable 5 の routine に流すと、コンプライアンス問題が静かに生まれる。
結論 — システムを作れ
- Fable 5 は速いチャットツールではない。複利するシステムの基盤 (substrate) だ。
- 初めて一般公開された Mythos クラスモデルは「より速くプロンプトされる」ために出荷されたのではない。あなたがその周囲に作る自己改善システムの orchestrator になるために出荷された。
- 能力のヘッドライン — 数日セッション、サブエージェント委任、vision 自己チェック、蓄積されるメモリ — は、モデルの周囲のシステムが仕事をして初めて価格に見合う。
- Anthropic 自身の実験がその差を可視化している。Parameter Golf: 独立 verifier 付きの Fable 5 はより大きなアーキテクチャ変更を探索し、負の中間結果を突き抜けて、Opus 4.7 比で 約 6 倍の改善を達成した。Continual Learning Bench: メモリ付き Fable 5 は 5 段階進行を完走し検証カバレッジ 73%、対する Opus 4.7 は 17%。どちらの比較でも、両側のモデルは同じものだ。変わったのは周囲のシステムである。
- compound stack のうち、まだやっていない層を 1 つ選ぶ — おそらく verifier サブエージェント (step 06)、state file (step 11)、vision-verify (step 13) のどれか — そして明日それを追加する。その次はもう 1 つ。
- 自己改善はモデルの性質ではなく、システムの性質だ。システムを作れ。